The Google File System
简介
GFS 发表于 2003 年的 SOSP ,Google 基于 GFS 用大量相对廉价的机器承载依赖大量数据的应用。GFS 将文件分为多个 chunk 存储,一个 chunk 冗余三份并存放于 chunkserver,client 直接与 chunkserver 通信进行读写,而 master 只管理元数据。GFS 被设计于承担面向顺序读写大文件的工作负载,且适用于写完就只读的情况。
个人读完论文后的几个感想:
- 简单粗暴
- 实在是太简单粗暴了。
- 租约的思想
- 收敛分布式文件读写的全局协商到单机。
- Master
- 绝大多数时候没有 Master 的单点通信问题。
- 特定负载特化
- 被特意设计为 append-only 和写后只读的工作负载。
- 弱一致性
- 这是双刃剑,这使得 GFS 可以简单粗暴地应对一些情况,但是需要业务充分理解松弛一致性模型后自己在上层做容错。
有人说 GFS 的意义在于展示现实大规模分布式系统的设计,并反映了工业界与学术界 concern 点的差异:
GFS 论文发表在 2003 年的 SOSP 会议上,这是一个有关系统的顶级学术会议。通常来说,这种会议的论文标准是需要有大量的创新研究,但是 GFS 的论文不属于这一类标准。论文中的一些思想在当时都不是特别新颖,比如分布式,分片,容错这些在当时已经知道如何实现了。
- 这篇论文的特点是,它描述了一个真正运行在成百上千台计算机上的系统 ,这个规模远远超过了学术界建立的系统。并且由于 GFS 被用于工业界,它反映了现实世界的经验,例如对于一个系统来说,怎样才能正常工作,怎样才能节省成本,这些内容也极其有价值。
- 提出在当时非常异类的观点: 存储系统具有弱一致性也是可以的 。当时,学术界的观念认为,存储系统就应该有良好的行为,如果构建了一个会返回错误数据的系统,就会像多副本系统一样,那还有什么意义?为什么不直接构建一个能返回正确数据的系统? GFS 并不保证返回正确的数据,借助于这一点,GFS 的目标是提供更好的性能 。
- 在一些学术论文中,你或许可以看到一些容错的,多副本,自动修复的多个 Master 节点共同分担工作,但是 GFS 却宣称使用单个 Master 节点并能够很好的工作 。
用户接口
GFS 提供了类似 POSIX 的接口,其中 create、delete、open、close 和 POSIX 类似,而 read、write、record append 有所不同。
理解 write、record append 的语义和行为有助于理解 GFS 的一致性模型:
- write
- 随机写,将任意长度的数据写入文件的特定 offset 。
- record append
- 追加写,将长度不大于 chunk size 的数据写入文件的末尾,record write 具有特殊的 原子性 (此原子性需要结合实现理解)。
read、write、record append 接口允许多个客户端读写同一个文件。
核心思想
- 将文件分为大小相同的 chunk,每个 chunk 在多个 server 上冗余并 由 master 授予一个 server 租约将其作为该 chunk 的 Primary,由 Primary 串行化该 chunk 的并发操作以及负责一致性确认
- 不保证操作能返回正确的数据,而是由用户约束操作以获得预期的表现。
设计观点
- 大规模分布式系统的故障是易见的
- 自动容错,因为大规模分布式系统故障是易见的
- 存放大量数据,文件通常很大
- 做特定优化,如块大小为 64 MB ,获取和存储元数据的成本降低,且将元数据可以保留在内存中。
- 关注吞吐量而非延迟
- 目标应用决定
- 读工作负载分为顺序流式读取大量数据和随机读取少量数据
- 性能敏感的应用应该批量且排序随机读。
- 写工作负载,文件通常只写一次,随机写很少
- 做特定优化,性能敏感的应用需要注意访问方式
- 明确一致性,保证语义
- 提供原子顺序写能力
关键结构

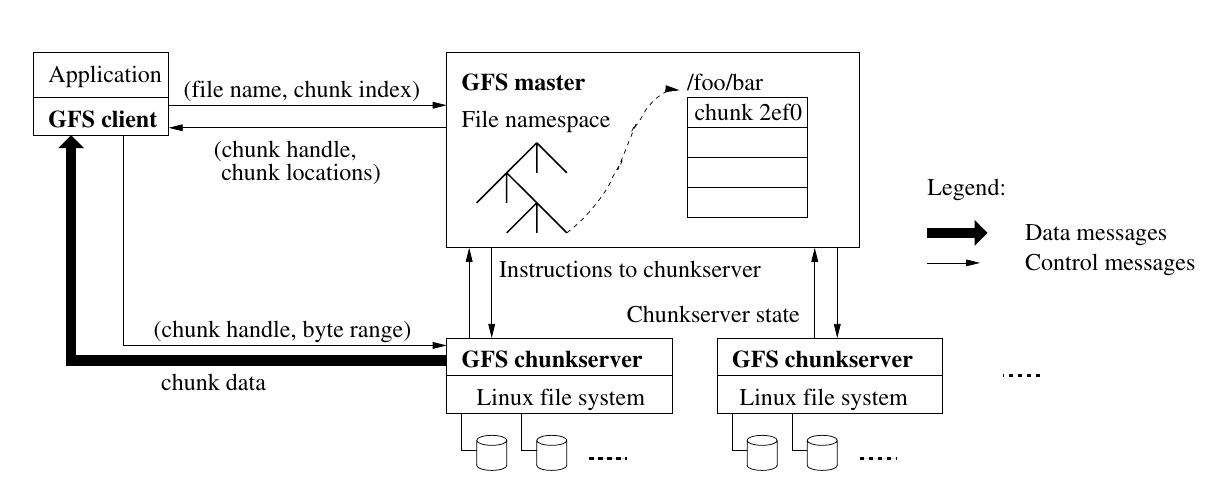
chunk
存储在 GFS 中的文件分为多个 chunk 。
- chunk 大小为 64M,存储在磁盘中
- 每个 chunk 在创建时 master 会分配一个不可变、全局唯一的 64 位标识符(chunk handle)
- 默认情况下,一个 chunk 有 3 个副本,分别在不同的 chunkserver 上
master
职责:维护文件系统的 metadata,负责 chunk 的迁移、重新平衡(rebalancing)和垃圾回收。此外,master 通过心跳与 chunkserver 通信,向其传递指令,并收集状态。
为了简化设计,GFS 只有一个 master 进行全局管理。
master 在内存中存储 3 种 metadata,如下:
- namespace (nv)
- 文件名 -> array of chunk handles or chunk ids 的映射;(nv)
- chunk handles -> 版本号(nv)、list of chunkservers(v)、primary(v)、租约(v)
其中, 标记 nv(non-volatile, 非易失) 的数据需要在写入的同时存到磁盘,标记 v 的数据 master 可以在启动后查询 chunkserver 集群 。
这里之所以 chunk server 列表、主 chunk 位置、租约不用记录,是因为重启时,对于第一个 master 可以再次询问 chunk 服务器得到,而对于另外两个 master 可以等待 60 秒过期。
这里 nv 的数据会以 log 形式存在磁盘,并进行一些 checkpoint ,这样 master 可以从最近的 checkpoint 开始恢复自己的状态。
client
向 master 询问文件 metadata,然后根据 metadata 中的位置信息去对应的 chunkserver 获取数据。
chunkserver
存储 chunk
关键过程
操作文件元数据
当 client 创建或写入文件时,需要创建新的 chunk handler,此过程是在 master 上进行的,并发安全性由 master 保障。
读
- client 将 文件名和 offset 转为文件名和 chunk index,向 master 发起请求
- master 在内存中的 metadata 查询对应 chunk 所在的 chunk handle 和 chunk locations 并返回给 client
- client 将 master 返回给它的信息缓存起来,用文件名和 chunk index 作为 key(注意:client 只缓存 metadata,不缓存 chunk 数据)
- client 会选择网络上最近的 chunkserver 通信,并通过 chunk handle + chunk locations 来读取数据
一些细节:
- 对于跨 chunk 读取, GFS 将其拆分成多个单 chunk 内的读取
- 应用程序应该容忍数据不一致的情况
- 读文件可以从任意 chunk 读
写(变更)
写的实现,write 和 record append 有所不同。
write(基本变更流程)
- client 向 master 询问 Primary 和 Secondary ,以及 Primary 的租约时长。如果没有选出 Primary ,则 master 选择一个版本号与 Master 记录一致的 Chunk 副本作为 Primary ,master 增加 Chunk 版本号并落盘,并通知对应 chunkserver Primary 和 Secondary 信息和新版本号,并授予 Primary 一个租约,60 秒内 Primary 可以作为 Primary。
- master 返回 Primary 和 Secondary 的信息,client 缓存这些信息,只有当 Primary、Secondary 不可达或者身份不一致或者租约过期才再次联系 master 。
- client 将追加的记录发送到 Primary 和 Secondary,server 会缓存这些记录。
- 一旦 client 确认每个 chunkserver 都收到数据,client 向 Primary 发送写请求,Primary 可能会收到多个连续的写请求,会先将这些操作的顺序写入本地
- Primary 做完写请求后,将写请求和顺序转发给所有的 Secondary,让他们以同样的顺序写数据;Secondary 完成后应答 Primary
- Primary 应答 client 成功或失败,如果出现失败,client 需要重试。只有所有 Secondary 都写成功后 Primary 才能返回成功。
- 如果 client 失败,需要重新发起整个过程。
一些细节:
- 写文件只能从 Primary Chunk 写
- client 不知道文件有多长,因为其他 client 可能会写
- 授予租约可以将 master 从数据更新中解放出来,并且利用 Primary 本地写将分布式写串行化,使得所有副本写入顺序一致
- 版本号只在 Master 节点认为 Chunk 没有 Primary 时才会增加,版本号一致不代表数据一致,版本号和租约授予有关,和数据新旧无关
- 当 master 发现 Primary 不可达时,会等到 Primary 租约过期再授予新 Primary 租约,这是为了防止脑裂 。
写入失败后,虽然版本号都一样,但是实际上数据是不一致的,因为写入操作并不是原子的,此时某些 Secondary 的 Chunk 数据是残缺的,但是如果客户端重新发起写请求并且成功了,那么追加的数据会在副本中相同位置存在。
record append
record append 在论文中被称为 atomic record append,遵循基本变更流程,但是有些附加逻辑,比如 client 需要先确认发送给 Secondary 成功,再发送给 Primary。Primary 收到后先确认是否会超出当前 chunk 的 size ,如果超出,填充当前 chunk 剩下的空间,并让 Secondary 做相同的操作,然后告诉 client 该操作应该在下一个 chunk 重试。如果当前 chunk 空间足够,则追加到尾部,并告知 Secondary record 在相同的位置,最后通知 client 操作成功。
一致性
write 和 record append 的区别
在写入跨 chunk 数据时,写入会被分成多个操作,write 和 record append 在处理跨 chunk 操作的行为是不同的。最大的区别在于 write 不保证跨 chunk 操作的原子性,而 append 保证 。
例子1:目前文件有两个 chunk,分别是 chunk1 和 chunk2。client1 在 54MB 的位置写入 20MB 数据。同时,client2 也在 54MB 的位置写入 20MB 的数据。两个 client 都写入成功。
这时 client1 需要向 chunk1 和 chunk2 分别写 10MB,client2 同理,这里有四个操作。我们知道,GFS 保证同一个 chunk 的操作是串行的,但是不保证多个 chunk 的操作的 _原子性_ ,假设这里在两个 chunk 上的执行顺序分别是 ~1->3~ 和 ~4->2~,那么虽然 client 都收到成功的响应,但实际上的数据存储是不符合我们的预期的。例子2:目前文件有两个 chunk,分别是 chunk1 和 chunk2。一个客户端在 54MB 的位置写入 20MB 数据,写第一个 chunk 成功,写第二个 chunk 失败,最终写入失败。例子3:目前文件有一个 chunk,为 chunk1。一个客户端在 54MB 的位置追加一个 12MB 的记录,最终写入成功。
record append 限制了 append 的 size 不得大于 chunk 并在面对跨 chunk 写入时新建 chunk 并让 client 重试,达到原子 append 的效果。原子性的含义
GFS 的原子性指的是写操作是否是原子的,接上节我们知道,write 不具有原子性而 record append 具有。
多副本之间不具有原子性
GFS 中一个 chunk 的副本之间是不具有原子性的,不具有原子性的副本复制行为表现为:一个写入操作,如果成功,那么它在所有的副本上都成功;如果失败,则有可能是一部分副本成功,而另一部分副本失败。
在这样的行为下,失败会导致以下后果:
- write 在写入失败后,虽然客户端可以重试,直到写入成功,达到一致的状态,但是如果在重试成功以前,客户端出现宕机,那么就变成永久的不一致了。
- record append 在写入失败后,也会重试,但是与 write 的重试不同,它不是在原有的 offset 处重试,而是在失败的记录后面重试,这样 record append 留下的不一致是永久的,并且还会出现重复问题。如果一条记录在一部分副本上写入是成功的,在另外一部分副本上写入是失败的,那么这次 record append 就会将失败的结果告知客户端,并且让客户端重试。如果重试后成功,那么在某些副本上,这条记录就会被写入两次。
从以上结果可以得出结论:record append保证至少有一次原子操作(at least once atomic)。
元数据一致性
元数据的操作都是由单一的 master 处理的,并且操作通过锁来保护,所以保证了原子性,也保证了正确性。
文件数据的一致性
GFS 把自己的一致性称为 松弛一致性模型(relaxed consistency model) 。
基本概念,对于一个文件中的区域:
- 无论从哪个副本读取,所有客户端总是能看到相同的数据,这称为 一致的(consistent) 。
- 在一次数据变更后,这个文件的区域是 一致的 ,并且客户端可以看到这次数据变更写入的所有数据,这称为 界定的(defined) 。
GFS 论文总结了其松弛一致性:
| 状态 | write | record append |
|---|---|---|
| 成功串行写入 | defined | defined 的数据区域夹杂不一致的数据区域 |
| 成功并行写入 | 一致但不 defined | defined 的数据区域夹杂不一致的数据区域 |
| 写入失败 | 不一致 | 不一致 |
- record append 成功写入
- 因为会填充数据,所以不一致。
- record write 写入失败
- 即使 client 及时重试,依旧会有部分 server 存多份数据。
- write 成功并行写入
- 会有前文提到的数据混杂的情况。
- write 写入失败
- 虽然失败可以 client 重试达到最终 defined,但是最坏的情况下,client 宕机不会重试。
应用需要适应松弛一致性
这种松弛一致性初听感觉不可思议,在这种保证下想要正确使用 GFS 需要一些原则:
- 依赖追加而不是覆盖
- 设立检查点
- 写入自校验
- 自记录标志
场景1:在只有单个客户端写入的情况下,按从头到尾的方式生成文件。
- 方法1:先临时写入一个文件,在全部数据写入成功后,将文件改名为一个永久的名字,文件的读取方只能通过这个永久的文件名访问该文件。
- 方法2:写入方按一定的周期写入数据,在写入成功后,记录一个写入进度检查点,其信息包含应用级的校验数(checksum)。读取方只校验和处理检查点之前的数据。即便写入方出现宕机的情况,重启后的写入方或者新的写入方也会从检查点开始,继续写入数据,这样就修复了不一致的数据。场景2:多个客户端并发向一个文件尾部追加数据,就像一个生产消费队列,多个生产者向一个文件尾部追加消息,消费者从文件中读取消息。
- 方法:使用record append接口,保证数据至少被成功写入一次。但是应用需要应对不一致的数据和重复数据。
- 为了校验不一致的数据(填充数据),为每条记录添加校验数,读取方通过校验数识别出不一致的数据,并且丢弃不一致的数据。
- 对于重复数据,可以采用数据幂等处理。具体来说,可以采用两种方式处理。第一种,对于同一份数据处理多次,这并无负面影响;第二种,如果执行多次处理带来不同的结果,那么应用就需要过滤掉不一致的数据。写入方写入记录时额外写入一个唯一的标识(identifier),读取方读取数据后,通过标识辨别之前是否已经处理过该数据。评价
GFS 的设计哲学就是简单够用,其一致性保证对应用来说是非常不友好的,这个问题在 GFS 推广初期不明显,因为初期的用户就是 GFS 开发者,他们深知如何正确使用 GFS,随着后续推广,GFS 暴露出包括但不限于一致性保证的问题,这也使得 HDFS 放弃了 GFS 的一致性模型。
Marshall, Kirk, McKusick, et al. GFS: Evolution on Fast-forward. Communications of the ACM, 2009.
此外,GFS 的单 master 带来扩展性(处理速度和内存存不下 metadata)和容错的问题。
Why
- 为什么单 master 能很好工作
- 弱一致性如何容忍
- 异地副本的难点在于
- 为什么是 master 主动 ping chunk server ?可能是为了方便切主的实现。
- 如何将 GFS 变得更一致:https://zhuanlan.zhihu.com/p/187542327
参考资料
- MIT 6.824
- 《The Google File System》
- 《分布式系统与一致性》
- https://zhuanlan.zhihu.com/p/354450124
- http://duanple.com/?p=202