BigTable
引导
如何学习这种架构?围绕哪些问题进行学习?
- 先快速看一下 QuickStart 有个直观认识。
- 阅读、查资料猜它怎么实现。
- 思考用了什么技术,对后面的技术产生什么影响。
简介
2006 年,Google 在 OSDI 发布了 Bigtable 论文,其设计和实现开始于 2004 年,在 2006 年已经有 100 个 cluster 部署,支撑众多业务,其中最大的 cluster 在数千台机器上管理了 200TB 的数据。
Bigtable 是 Google 的三驾马车之一,在 Google 的基础架构生态中,Bigtable 位于 GFS 之上,为上层应用提供了一个中间层存储,致力于提供一个解决方案来满足 Google 内部差异较大的不同业务场景需求,可以容纳 PB 级数据、可以满足线上实时查询的低延迟、大量(半)结构化数据,并支持随机写入、高读写速率、高效的 scan、多版本等特性。
如果要下个定义,那么 Bigtable 是一个分布式的、排序的、支持行内事务的、半结构化的、支持多版本、支持在线和离线场景的列簇数据库 (不完全是)。
QuickStart
https://www.w3cschool.cn/hbase_doc/hbase_doc-m3y62k51.html
数据模型
Bigtable 提供给用户的数据模型是排序大表 + 列簇。
cluster 是多个进程组成的一个 Bigtable 实例,一个 cluster 可以容纳多个 table ,table 是一个稀疏的、分布式的、一致的、多维的一个 map 。用 row 、column、timestamp 索引 map 得到 cell ,其中 row 、 column 和 cell 都是 bytes ,并且 column key 的格式为 family:qualifier 。
(row: bytes, column: bytes, time: int64) -> (cell: bytes)
论文中的网页存储例子,可以说明这个数据模型的使用方式:
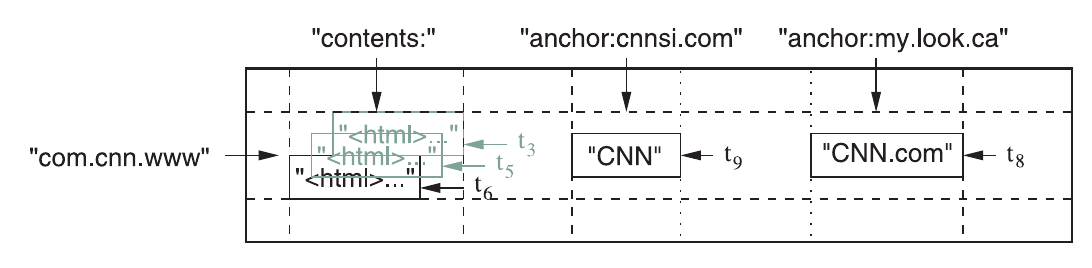
#+begin_example
Fig. 1. A slice of an example table that stores Web pages. The row name is a reversed URL. The contents column family contains the page contents, and the anchor column family contains the text of any anchors that reference the page. CNN’s home page is referenced by both the Sports Illustrated and the MY-look home pages, so the row contains columns named anchor:cnnsi.com and anchor:my.look.ca. Each anchor cell has one version; the contents column has three versions, at timestamps t3 , t5 , and t6.
#+end_example>
table 中,rows 被划分为多个 tablets ,tablet 作为存储和负载均衡的最小单位,columns 被划分为多个 column families ,column family 作为资源分配和访问控制的单位。
table 按行关键字的字典序维护,一个 row 下的数据读写是原子的,换句话说 bigtable 只提供行内事务,不提供跨行事务。table 中的 rows 被划分为多个 tablet ,单个 tablet 内的 row 是连续的。tablet 是存储和负载均衡的最小单位,这样做可以较好地应对具有局部性的场景,当数据访问具有局部性,只需要访问存放这几个 tablet 的机器即可(比如网页存储这个例子,一般一个域名下的 url 在字典序上是连续的)。一般,一个 tablet 大小约 100MB~200MB。
table 的 columns 被划分为多个 column families ,而 column key 的形式为 family:qualifier 。用户在创建 table 时必须先声明含有的 column family ,随后可以在 column family 下任意创建 column 。column family 是资源统计和访问控制和磁盘内存分配的单位。同一列簇下的列的数据类型一般是相同的,Bigtable 会将一个列簇下的数据合并压缩。
table 的 cell 可以具有多个版本,由 timestamp 标识不同版本(int64),可以由 Bigtable 默认分配毫秒级时间戳,也可以由应用自行指定(保证不重复),一个 cell 内的不同版本按 timestamp 降序排序。Bigtable 支持两种列簇级的垃圾回收机制配置,比如 cell 保存最新 n 个版本、保存近 7 天的版本。
实现
基础架构
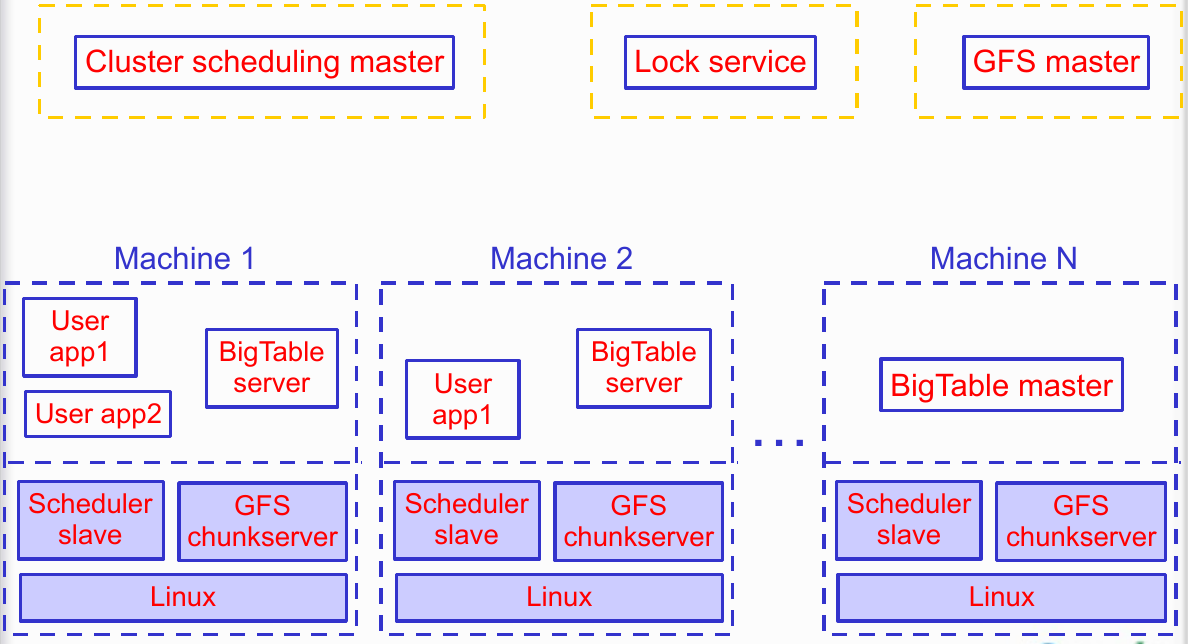
Google 的基础架构是一层层叠上去的,Bigtable 基于以下基础设施:
- GFS
- 底层存储,持久化存储数据。
- Scheduler
- 在集群上执行任务,拉起 Bigtable 服务。
- Chubby
- 分布式锁,进行选主、行定位和维护 schema 。
- MapReduce
- 分布式计算实现,可以读写 Bigtable (离线任务)
集群组件
一个 Bigtable Cluster 由以下服务构成:
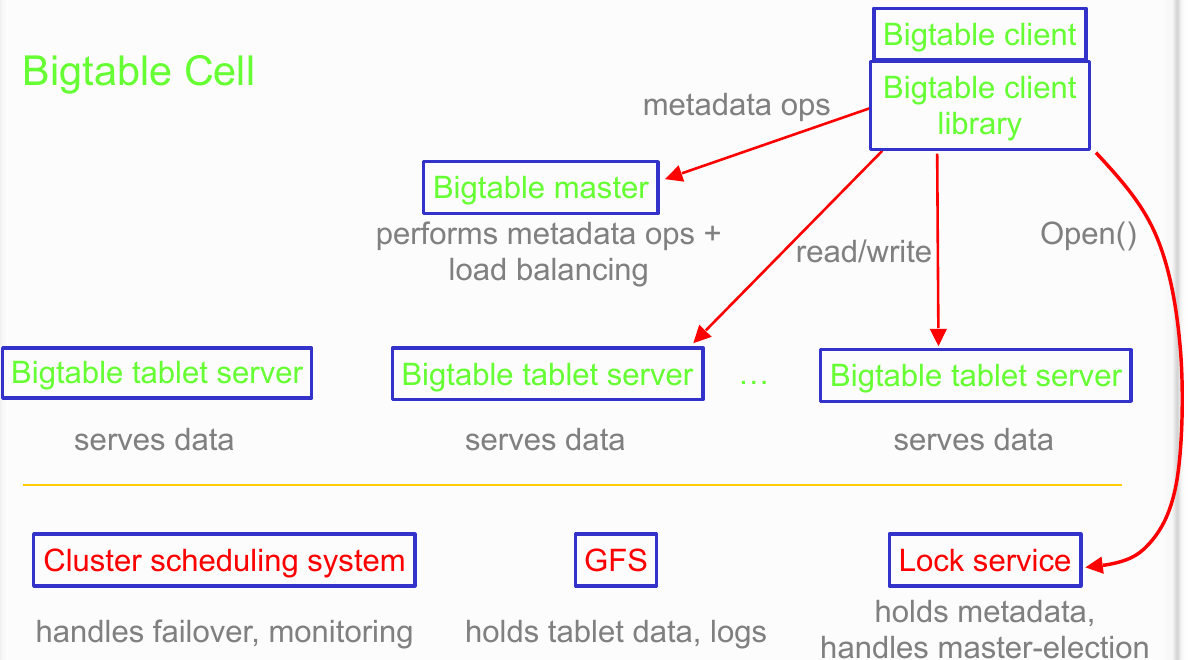
master 服务器
master 服务器负责将 tablet 分配到 tablet 服务器,检测 tablet 服务器的加入和退出,平衡 tablet 服务器负载,GFS 文件的垃圾回收,处理 schema 的变化。
master 服务器由使用 Paxos 算法的 Chubby 保证分布式一致且可用,由 Chubby 实现以下保证:
- 最多只有一个活动的 master
- 存储 boostrap location
- 发现 tablet 服务器以及 finalize tablet 服务器的死亡
- 保存 Bigtable schema 信息
- 存储访问控制列表
tablet 服务器
tablet 服务器管理一组 tablet ,负责已加载的 tablet 的读写请求,分割过大的 tablet ,tablet 服务器只负载管理,从数据存储角度可以认为是无状态的,底层存储由 GFS 负责。
实际上,tablet 只维护管理 memtable (v),数据存储在 GFS (nv)上的 SSTable 和 Commit Log (WAL) 里,可以认为 tablet 服务器只是一个 proxy。
客户端
客户端不依赖 master 进行数据传输,也不依赖 master 获得 tablet 的位置信息,客户端几乎不会和 master 交互。
数据结构
tablet 位置信息
tablet 存放位置:
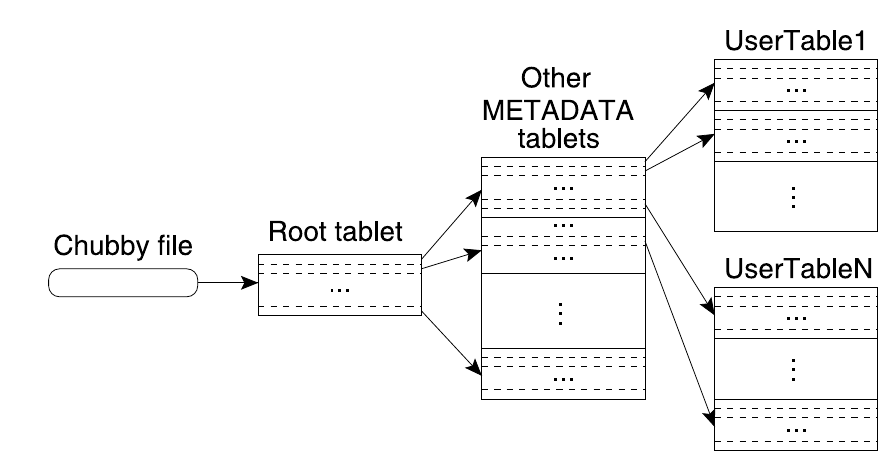
- Chubby File
- 存放 root tablet 位置信息的文件。
- Root Tablet
- 存放 METADATA table 的 tablets 的位置信息,同时其自身也是 METADATA table 的一个 tablet 。Root Tablet 不会分裂,这使得存放 tablet 位置的数据结构的层级不超过三层,也使得客户端在获取 tablet 位置信息时不会经常回源到 master。
- METADATA Table
- 存放所有 tablets 的位置信息的一个 table ,行关键字(tablet 标识 + 结束行)下存储了 tablet 的位置。如果限制该 table 的 tablet 大小不超过 128MB ,每行大概存放 1KB 数据,则 METADATA 最多索引约 \(2^34\) 个 tablet ,而其本身最多有约 \(2^17\) 个 tablet ,占空间约 \(2^44\) 字节共 16 TB 。对于 METADATA Table 只会把特定信息加载到内存中,比如 location 列簇。
tablet 的 LSM-Tree 和 WAL
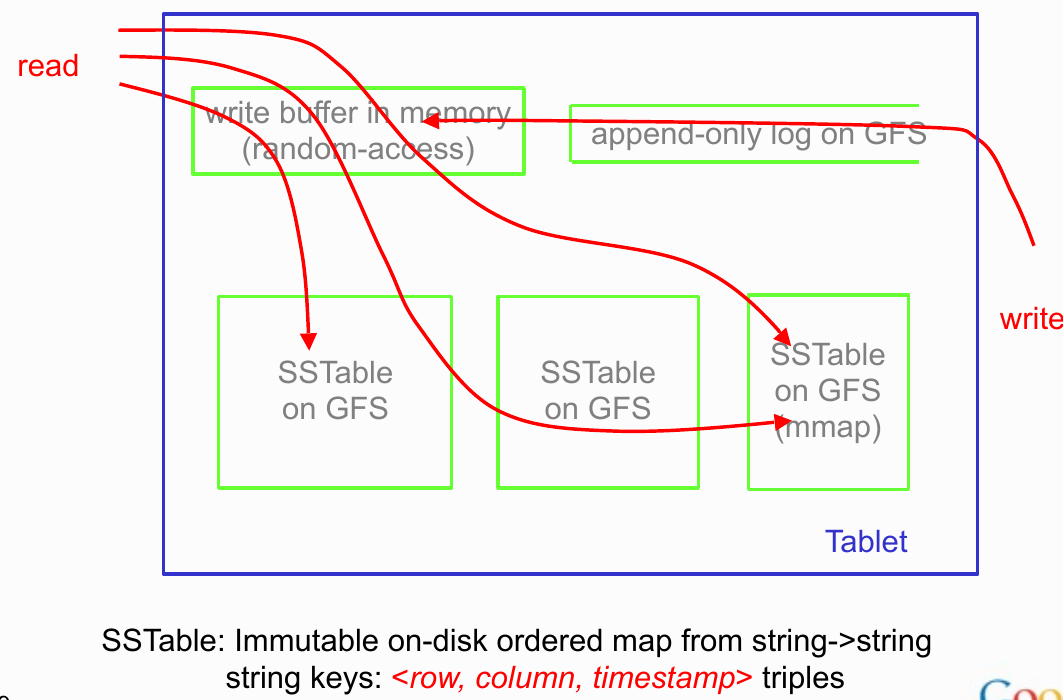
tablet 服务器上会维护其管理的 tablet 的 LSM-Tree ,由内存中的 memtable 和 GFS 上的 SSTable 组成,SSTable 的排序 key 也为 <row, column, timestamp> 。
我们知道,对于一个 tablet ,其状态只由 GFS 上的 SSTable 和 Log 决定,Log 代表还未被固化到 SSTable 的操作,实际上实现是 WAL 的。
实际上,一个 tablet 会对应多个 SSTable 集合,这是因为 Bigtable 的群组设置允许将一组列簇放到一组 SSTable 中。至于 memtable 会不会拆分,结合单行事务的实现,我觉得是不会拆分,但是这会过度碎片化导致 dump SSTable 频繁且细碎。
另外,这里的 LSM-Tree 和节点论文中描述的 n 层模型有些不同,参考后面的 compaction 过程,和传统 LSM-Tree 略有不同。
流程
单行事务
Bigtable 将一个 table 内的 rows 划分为多个 tablet,并以 tablet 为分派的单位,也就是说,对于任意一行,必然只对应一个 tablet,而对于任意一个 tablet,最多只有一个 tablet server 负责,这样对于单行事务实现就转化为单机问题。
对于单行事务如何实现,可以参考论文中的以下描述:
- As a result, concurrency control over rows can be implemented very efficiently. The only mutable data structure that is accessed by both reads and writes is the memtable. To reduce contention during reads of the memtable, we make each memtable row copy-on-write and allow reads and writes to proceed in parallel.
- Each cell in a Bigtable can contain multiple versions of the same data; these versions are indexed by timestamp.
大致可以猜测是使用 COW 加 MVCC 保证 ACID 。
客户端获取 tablet 位置
客户端会缓存 tablet 位置,如果不知道或发现缓存失效,则会递归向上地在 METADATA Table 中查找,再递归向下地回源,回源时会获取一批,而不只是当前所需的信息,同时客户端还会 prefetch 。
tablet 服务器发现
当一个 tablet 服务器启动时,使用 Chubby 创建一个文件锁,master 监控所在目录以发现 tablet 服务器,tablet 服务器会不断尝试获取文件独占锁,否则锁过一段时间失效,当文件不存在,则 master 能得知该 tablet 服务器故障。
master 也会不断向 tablet 发送心跳,如果 tablet 服务不可达或告知 master 自己不可用,则 master 会尝试获取对应文件的独占锁,如果能获取成功,则说明 Chubby 可用,获取后会删除该文件。
master 拉起
拉起过程:
- 在 Chubby 获得 master 锁
- 扫描 Chubby 目录找到可用的 tablet 服务器
- 与 tablet 服务器通信发现 tablet 的分配
- 扫描 METADATA table 发现 tablet 集合,区分出待分配的 tablet ,并将其分配
- 如果发现 Root Tablet 未分配,则先将其分配
- 如果发现有 METADATA Table 的 tablet 未分配,则先将其分配
另外,为了保证一个 Bigtable 集群不会因为与 master 和 Chubby 间的网络问题而变得脆弱,如果 master 的 Chubby 会话过期了,master 会自杀。
tablet 分配
master 存放 tablet 在 tablet 服务器的分配情况,一个 tablet 同时只会分配给一个 tablet 服务器。
master 的不可用不会影响 tablet 的已有分配。
当确认 tablet 服务器不可用, master 会将分配过的 tablet 标记为待分配。
tablet 集合只有在以下情况才会发生变化,而 master 负责这些变化因此能追踪 tablet 集合的变化:
- 表被创建
- tablet 合并
- tablet 分裂
tablet 分裂是特殊的,因为这是由 tablet 服务器发起的:
- 记录到 METADATA Table 以提交
- 通知 master
- 如果通知丢失,在 master 维护的 tablet 集合则存在过期 tablet ,当 master 分配该 tablet 的时候会 tablet 服务器会发现异常(因为对应 METADATA Table 中该 tablet 对应的键值是不完整的)。
tablet 读写
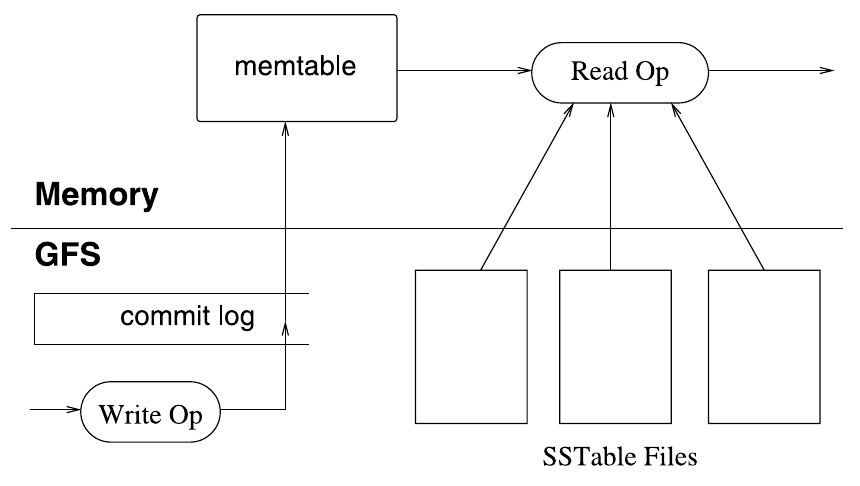
写:
- tablet 客户端检查是否合法,是否具有权限
- tablet 服务器检测是否合法,是否具有权限(从 Chubby 读取一个允许的写者列表)
- 写入 commit log (WAL),batch 提交
- 写入 memtable
读:
- tablet 客户端检查是否合法,是否具有权限
- tablet 服务器检测是否合法,是否具有权限(从 Chubby 读取一个允许的写者列表)
- 在 LSM-Tree 上读取(布隆过滤器)
另外,分割和合并 tablet 不阻塞读写,这得益于 LSM-Tree 的结构。
memtable compaction
- minor compaction
- memtable 条目数过多时,创建新 memtable ,冻结旧 memtable 并转化为一个 SSTable 。
- merging compaction
- 当 SSTable 文件过多时,将多个 SSTable 和 memtable 合并为一个 SSTable ,结束后删除对应 SSTable 和 memtable 。
- major compaction
- 合并所有 SSTable 的 merging compaction ,Bigtable 会周期性进行这个操作,major compaction 输出的 SSTable 不含有过期的数据 。
Bigtable 会进行 merging compaction 限制 SSTable 数量,进行 major compaction 回收资源,并保证已删除的数据确实被删除。
redo
log 又被称为 redo 日志,每个 SSTable 都与 log 上的一点对应,这一点被称为 redo 点,实际上,redo 点可能不是行级的(想想这是为什么),每次 tablet 在新的 tablet server 加载的时候,新的 tablet server 需要把 redo 点之后的 log 加载为 memtable ,实际上,redo 点之后的 log 就是未持久化为 SSTable 存到 GFS 中。
性能调优
局部性群组(Locality Groups)
用户可以将多个列簇组织为一个局部性群组,对于每个局部性群组会生成单独的 SSTable ,这样的好处是可以分离冷热数据,减少 scan 的开销,并且我们可以认为同个群组下的数据相似度更高。
对于每个局部性群组,可以设置其是否放入内存,是否压缩及压缩格式。
读二级缓存
tablet 服务器针对 SSTable 使用二级缓存:
- 扫描缓存
- 缓存 SSTable 含有的 KV ,针对热点数据。
- 块缓存
- 缓存从 GFS 读取的 SSTable ,针对局部性(顺序读、局部性群组内读)。
布隆过滤器
用户可以为局部性群组指定对应布隆过滤器。
写提交日志优化
GFS 有时会写性能会抖动, tablet 有两个写日志文件线程,每个写各自的日志文件,同时只会有一个活跃,日志有序列号,可以后续用于去重和排序。
提交日志共享优化
每个 tablet 服务器会将其负责的 tablet 下的所有更新 append 到同一个日志文件下,这样可以减少文件写,并提高 batch 写入的效率。
这样做的坏处就是 tablet 服务器不可用 tablet 再分配时 tablet 和日志文件之间不再具有亲和性,redo 过程会造成大量的无效读取。
master 会在后台会负责对日志文件按照 <table,row name,log sequence number> 排序,排序任务按 64MB 划分,并分派到多个 tablet 上。这样后续 redo 时 tablet 服务器就可以按需读取。
加速 tablet 恢复
在迁移 tablet 的时候,旧的 tablet 会先进行一个 minor compaction ,减少日志中的 uncompacted 状态数,然后在进行一个 minor compaction ,消除剩余的 uncompacted ,这样新的 tablet 服务器加载时就不需要进行 redo 了,但是可用性有损,因为这里第二次 compaction 是不可用的。
利用不可变性
SSTable append 创建,创建后就不写,这契合 GFS 的设计,这样后续对文件的访问容易做并发控制。另外 Memtable 中使用 COW ,允许读写并行。
SSTable 会注册在 METADATA Table 中,master 使用标记-删除法进行垃圾回收。
得益于此,tablet 分割时也容易对 SSTable 做分割,只需要简单地引用旧的 SSTable 。
压缩 SSTable
用户可以控制一个局部性群组的 SSTable 选择的压缩方法,下面描述一般选择的压缩方法。
对于压缩,需要考虑的是:每个 block 的大小约 64 KiB,防止太大不利于随机访问,防止太小导致开销 or 效果不好。普遍使用的算法是两遍压缩,即第一次压缩在大窗口下使用 BMDiff,第二次压缩在 16KB 的小窗口下使用快速压缩算法(Zippy),两次压缩的速率都很快,压缩在 100-200MB/s ,解压在 400-1000MB/s 。
Keys:
- 已排序的
<row, column, timestamp>的 bytes 使用前缀压缩
Values:
- 按类型将 Value 分组,比如 column family
- 对一个 family 的所有 values 进行 BMDiff 压缩
- BMDiff 对前 N 个 Value 的输出作为第 N + 1 个 Value 的字典
最终,使用 Zippy 对整个 Block 进行压缩
- 优化更局部性的重复
- 压缩 keys ,压缩跨 column family 的数据
在 Bigtable 存储 2.1B 的网页,key 为 url ,这样使得同一个 site 的 pages 被放在一起,既利于压缩发现共性 pattern 也利于 client 访问的局部性。在这个 case 中,直接对每个 page 使用 gzip 的压缩率大概是 28% ,而使用上面的两阶段压缩法则能获得 9%~14% 的压缩率。
思考:这里 BMDiff 和 Zippy work 的原因是?
评价
数据模型
当我们设计一个复杂的系统时,我们应该对这个系统做适当的抽象,这个抽象需要满足系统设计的目标,以抽象作为骨架和脉络,而实现它则是在其基础上填充血肉。MapReduce 是对分布式计算的一个成功的抽象,而 Bigtable 的数据模型是对分布式存储的一个成功的抽象。Bigtable 的一大贡献就是其数据模型,在那个年代,大家还在探索这种大集群下的存储系统该提供怎样的数据模型,能易于理解,满足业务开发需求,又能易于实现出可伸缩支持海量存储的系统。实际上,Bigtable 的 “排序大表 + 列簇”在当时并不新鲜,但被证明是一个非常成功的设计,能 cover 变化多样的业务需求(从线上到线下)。后来的 MegaStore 直接基于 Bigtable ,Spanner 的单 tablet 的存储也直接复用了 Bigtable 的版本。
顺序写只读文件
Bigtable 的一个贡献就是对 LSM-Tree 的应用,这个设计只会顺序写 SSTable 和日志文件,且写完就是只读的,将随机写转化为顺序写,这与 GFS 的设计极搭,,我们知道 GFS 就是为顺序写不可变文件特化的。只读 SSTable 的设计,简化了实现,如 tablet 分裂。基于 GFS ,使得 Bigtable 不用考虑底层冗余和 SSTable 一致性问题,也简化了实现。
后来,Bigtable 上 LSM-Tree 的实现也被开源到了 LevelDB 上,启发了其他很多开源项目。
tablet 挂掉恢复的问题
注意到 tablet 挂掉,在恢复期间会不可用。线上应用要挂 replication 和 cache 。
单行事务
一个有趣的事实是,多行事务天生就是不可扩展的,要求在多行间做同步,很可能会涉及到多节点协商的问题,基于 CAP 粗糙分析,此时 AP 只能取其一,非常难搞,所以 Bigtable 只实现单行事务。
而单行事务的实现也可圈可点,我有些怀疑 bigtable 不按照 column family 划分 tablet 而是按照 row 划分,就是为了方便地将行内事务转化为单机问题,消除分布式协商的过程。
不过未实现跨行事务也是 Jeff 对 Bigtable 最遗憾的一点。然而,你不提供,业务会想方设法自己搞,而大多数时候业务自己弄的实现基本都是有问题的,比如 MegaStore ,带来更多问题。后来 Jeff 实在看不下去,在 Spanner 提供了官方的分布式事务支持。
Google 三驾马车的风格
读完三驾马车,有几点印象尤为深刻:
- 简单实用,在够用的基础上做取舍,这种粗旷的感觉像是用羽毛笔在羊皮纸上书写。
- 像垒砖一样一层层垒上去,这三篇还是近二十年前的作品。Bigtable 基于 GFS 、Chubby 、Borg,10w 行 cpp 就实现出来了。这个打法像是在分布式上构建操作系统,接着在其上构建生态,如果想跟着打,会追得很辛苦,如果想走捷径取得局部成果,又后劲不足,给人被碾压的感觉。
- 业界独有的业务场景,成就了 Google 基础架构的价值,实际上 Google 的论文的贡献,其实践价值占很大一部分,GFS 是如此、MapReduce 是如此、Bigtable 也是如此,它们并不精巧,做了很多妥协,但却大巧不工,告诉大家一个实践可用的系统的设计可以是什么样子。
- 当其他公司还在考虑如何 Scale 时,Google 已经在思考如何廉价地 Scale。
架构设计得失
存储层基于 GFS 是一把双刃剑
Pros
- LSM-Tree 和 GFS 搭配得恰到好处,看起来十分优雅
- 基于分布式文件系统,分离数据库和底层存储实现
Cons
- 对可用性和性能的牺牲非常大
- 即使有多个副本,所有客户端只能读一个副本
- 做不到底层存储和 tablet 服务的亲和性
- 比较难实现完整的多机房副本
row 有序
因为有中心节点比较方便做split/move的操作,在 row key 有序的前提下可以尽可能让集群 balance ,而哈希 NoSQL 则不能这么做,而且也不能提供 scan 操作。
CP 存储系统的架构设计演进:我们在对什么维护一致性,SSTable or LSM-Tree ?
SSTable 不能完全代表 tablet 状态机的状态信息,LSM-Tree (准确来说是 SSTable + Log)才能完整地对应 tablet 的状态,当我们维护 SSTable 的一致性而不维护 memtable 的一致性时,潜台词是 memtable 是单机的,进一步是 tablet 是单机的。一个 tablet 只在一个机器上,一旦这个机器挂了需要让其他机器读 log 恢复,造成可用性问题。
再后来的应用用一致性协议维护多个复制状态机的一致性(比如 TiKV 的 RocksDB + Raft),RocksDB (LSM-Tree)存放单机复制状态机的状态,这样做的好处有:
- 达到底层存储和 proxy 的亲和性,可以读多个副本(Raft Follower Read),也可以更好地调度副本位置。
- Leader 挂了重新选出 Leader 就能快速恢复,因为在理想情况下任何时刻每个复制状态机的状态都是一致的,即使不一致,只要过半数的复制状态机可用,也能选出新的 Leader 立马服务,恢复时间短很多。
GFS 维护 SSTable 的一致性,而后来者维护 LSM-Tree 的一致性,这样做的坏处是:
- 需要付出额外的 CPU 和 Mem ,而且对于单行事务还是需要分布式协商。
- 会有脑裂问题
HBase 的解决方案是搞 slave region,找另外一个 RS 异步的从 WAL 里读数据放内存里,平时可以作为最终一致性的读写分离用,RS 挂的时候也可以直接从 slave region 所在的 server 上补上少量 delay 的 log 后直接服务,恢复时间也很短,用二倍的内存和不到二倍的 CPU 做了类似的事情。
日志聚合写入
本质上是用 redo 的开销换在线写入的开销,而 redo 的开销是可以通过离线排序减少的,所以可以说是用离线的开销换在线的开销。
数据模型暴露多版本
在数据模型层面支持多版本技术上是普遍都有的,但把多版本这个东西暴露在数据模型,对很多业务也是非常方便的。
CAP 取其二,AP 还是 CP ?
当时大家对这种大规模分布式系统环境的认识还并不系统,谈得最多的是 CAP ,CAP 不可兼得是一个定律,需要人们自行根据业务场景做取舍来设计系统,Bigtable 取其 CP (注意到 tablet 恢复的过程,知道 A 较差),当时还有一个项目是 Amazon 的 Dynamo 取其 AP ,不对 C 做保证,由上层应用自行处理。
说到这里,我们就不得不谈谈 Cassandra 了,可以认为 Cassandra 希望取 Dynamo 和 Bigtable 的优点,提供 CP 和 AP 的选择,但是 Cassandra 真的能 CP 吗?
本质上,当我们讨论一致性时,我们讨论的是客户端的可见性问题,
其实 Cassandra 是可调一致性,一致性换性能,Cassandra 底层完全看时间戳谁大谁赢来决定能读到什么,而不同机器的时间戳是有误差的。所以在误差内两个机器先后写一行数据,是可能先写的覆盖后写的,连最终一致性都不算了。如果 W+R>N 也算强一致,实际上已经同时满足 CAP 了,因为挂一个节点不耽误用。实际上,Cassandra 要么是 client 指定时间戳,要么以接受 client 请求的那个 server 的系统时间戳作为数据的时间戳。如果两个 client 同时请求不同的节点来写同一行数据,那么就相当于在读取的时候必须用两个不同机器的时间戳来比较了。这要是强一致性,那 CAP 就同时满足了。
不管如何,Cassandra 能提供的 C 和我们平常理解的那个 C ,是很不一样的,也很难对应到我们常讨论的那几个客户端可见性定义的一致性上(线性、顺序、因果、最终)。
可以试着构造反例,如果 client 决定 timestamp 如何,如果 server 决定 timestamp 又如何?言归正传,我认为 CP 比 AP 更重要,可以以 GFS 为前车之鉴: GFS 的设计哲学就是简单够用,其一致性保证对应用来说是非常不友好的,这个问题在 GFS 推广初期不明显,因为初期的用户就是 GFS 开发者,他们深知如何正确使用 GFS,随着后续推广,GFS 暴露出包括但不限于一致性保证的问题,这也使得 HDFS 放弃了 GFS 的一致性模型。
参考资料
- 《BigTable: A System for Distributed Structured Storage》 by Jeff Dean
- 《Bigtable: A Distributed Storage System for Structured Data》 by Fay Chang , Jeffrey Dean , Sanjay Ghemawat , Wilson C. Hsieh , Deborah A. Wallach , Mike Burrows , Tushar Ch,ra , ,rew Fikes , Robert E. Gruber
- Bigtable 论文中文翻译
- https://www.zhihu.com/question/19551534/answer/116874719
- https://www.slideshare.net/kyhpudding/dreaming-infrastructure
- Structure and Interpretation of Computer Programs, Second Edition