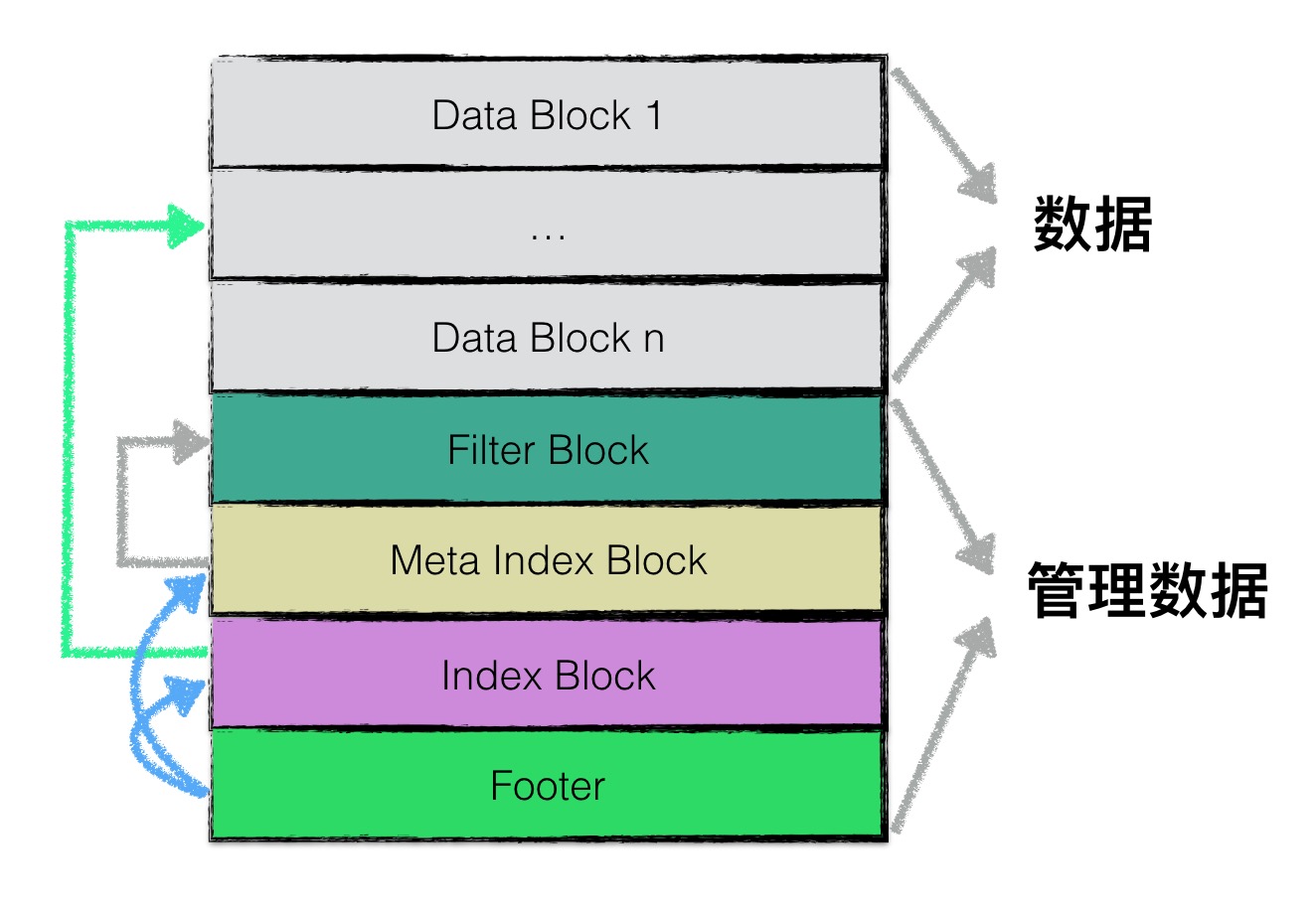
LevelDB SSTable
简介
Leveldb 内存中 MemTable 的数据达到阈值,会将数据 dump 到磁盘中形成 SSTable 文件。不同 SSTable 的 Key Range 是存在交集的,在读操作时,需要对所有的 SSTable文件进行遍历,影响读速度,后台需要定期合并部分 SSTable 文件,该过程称为 Compaction。随着 Compaction 的进行,SSTable 文件在逻辑上被分成若干层,由内存数据直接 dump 出来的文件称为 level 0 层文件,后期整合而成的文件为 level i 层文件,这也是 LevelDB 这个名字的由来。
文件格式
Block
SSTable文件按 4K 分 Block ,每个 Block 中,除了存储数据以外,还会存储两个额外的辅助字段:压缩类型和 CRC 校验码,LevelDB 默认采用 Snappy 算法 进行压缩。
| Data | Compact Type | CRC |
|---|---|---|
| Data | Compact Type | CRC |
| Data | Compact Type | CRC |
| Data | Compact Type | CRC |
Block 有以下种类,其中前四种 Block 具有先前提到的结构:
- data block :: 存储 key value 数据
- filter block :: 存储一些过滤器相关数据
- meta Index block :: 存储 filter block 的索引信息
- index block :: 存储 data block 的索引信息;
- footer :: 存储 meta index block 及 index block 的索引信息
Block Handler
由对应 Block 在 SSTable 文件中的偏移和大小组成。
Footer
Footer 位于文件的末尾,是定长 48 字节的,内容为一个 8 字节的 Magic Number 和两个 Block Handler —— index handle 和 meta index handle ,分别指向 Index Block 和 Meta Index Block 。
| Meta Block Offset (varint64) |
|---|
| Meta Block Size (varint64) |
| Index Block Offset (varint64) |
| Index Block Size (varint64) |
| Padding Bytes (0-36 Bytes) |
| Magic Number (8 Bytes) |
// kTableMagicNumber was picked by running
// echo http://code.google.com/p/leveldb/ | sha1sum
// and taking the leading 64 bits.
static const uint64_t kTableMagicNumber = 0xdb4775248b80fb57ull;Index Block
每条 KV 指向一个 Data Block ,Key 是一个大于等于对应 Block 最大 Key 且小于下一个 Block 最小 Key 的值,V 是一个 Block Handler 。
这里的 Key 是两个 Block 之间的最短的分割:
void FindShortestSeparator(std::string* start,
const Slice& limit) const override {
// Find length of common prefix
size_t min_length = std::min(start->size(), limit.size());
size_t diff_index = 0;
while ((diff_index < min_length) &&
((*start)[diff_index] == limit[diff_index])) {
diff_index++;
}
if (diff_index >= min_length) {
// Do not shorten if one string is a prefix of the other
} else {
uint8_t diff_byte = static_cast<uint8_t>((*start)[diff_index]);
if (diff_byte < static_cast<uint8_t>(0xff) &&
diff_byte + 1 < static_cast<uint8_t>(limit[diff_index])) {
(*start)[diff_index]++;
start->resize(diff_index + 1);
assert(Compare(*start, limit) < 0);
}
}
}Meta Index Block
每条 KV 指向一个 Filter Block ,目前 SSTable 只有一个 Filter Block 。
Data Block
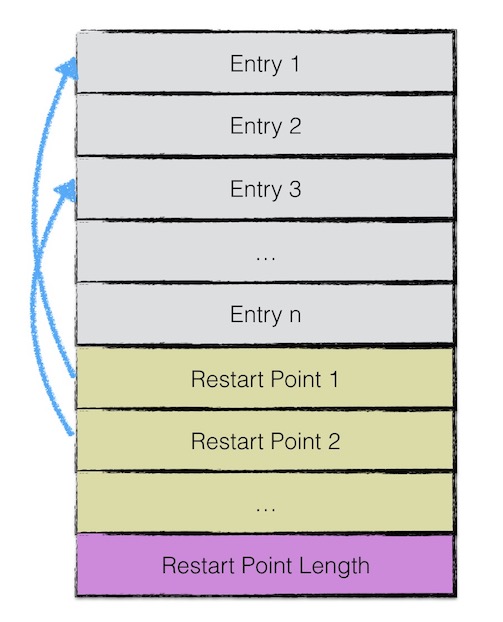
LevelDB 不会为每一个 KV 对都存储完整的 key,而是存储与上一个 key 非共享的部分,避免了 key 重复内容的存储。
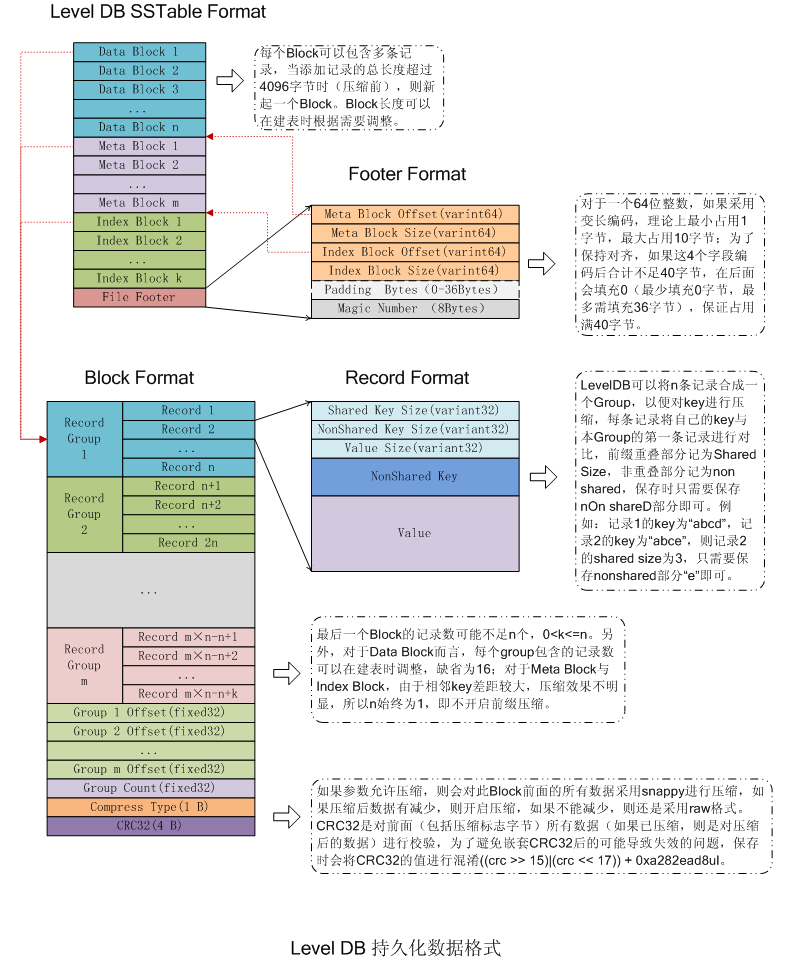
每间隔若干个 KV 对,将为该条记录重新存储一个完整的 key。重复该过程(默认间隔值为16),每个重新存储完整 key 的点称之为 Restart Point ,一组 KV 对(一组 Record)称为 Record Group ,一个 Group 的 Record 数量由 options_->block_restart_interval 决定,是固定的。
每个数据项的格式如下:
| Shared Key Len | Unshared Key Len | Value Len | Unshared Key Content | Value |
其中 int 类型以 varint 格式存储。
Filter Block
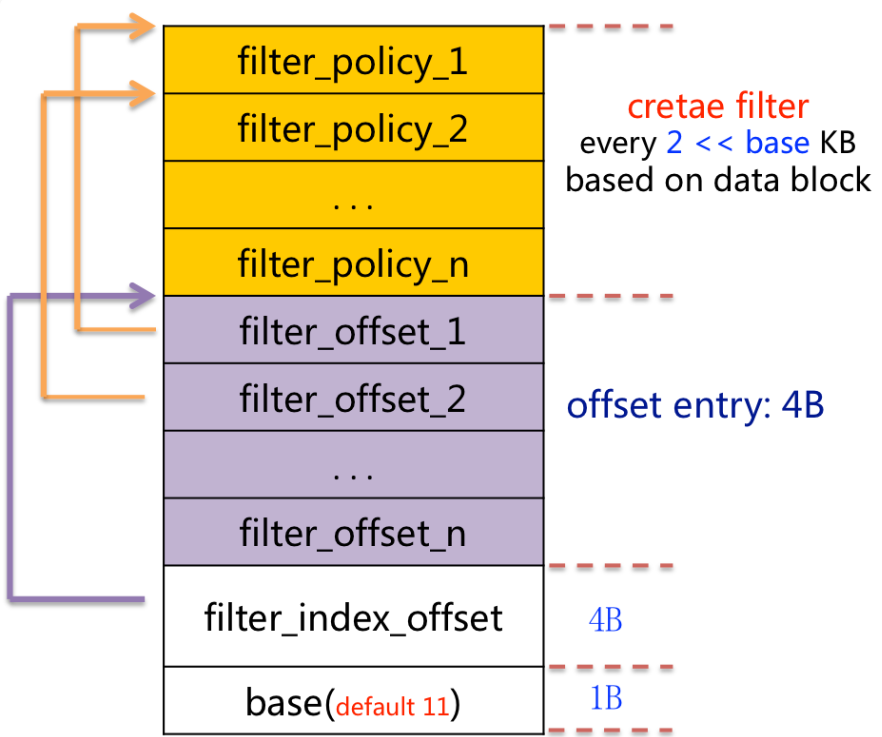
一个 SSTable 只有一个 filter block,其内存储了所有 block 的 filter 数据. 具体来说 filter_data_k 包含了所有起始位置处于 [base*k, base*(k+1)] 范围内的 block 的 key 的集合的 filter 数据。
流程
读
- 读 Index Block 找到对应 Data Block
- 在 Data Block 的 restarts 数组的基础上进行二分查找,确定 restart point 。
- 从 restart point 开始遍历查找。
写
SSTable 由 Immutable MemTable 转换得到。TODO
遍历
单路使用 TwoLevelIterator 进行遍历,多路使用 MergingIterator 进行遍历。
评价
- 转换随机写到随机读,写优化到顺序写,而对于读我们有 Cache 和 Filter 的方式降低开销。
- 可以尝试调整 Block Size ?