LevelDB LogFile
References
Intro
LevelDB 是 WAL 的,写入必须先写入 Log 才算成功,将 LevelDB 视为状态机,Log 文件就代表 LevelDB 的状态转移,LogFile 可以认为代表了当前 LevelDB 的状态,而 LSM-Tree 可以认为是 LogFile 状态的存储和索引方式,故障恢复时可以重放 Logfile 从 Snapshot 点重新构建 LSM-Tree 的 Memtable(SSTable 是持久化的,不需要重新构建)。
LogFile 的主要作用是:顺序化写入、故障恢复。
db/log_writer.h
Status Writer::AddRecord(const Slice& slice);
bool Reader::ReadRecord(Slice* record, std::string* scratch); // scratch as temporarily buffer
结构
db/log_format.h
enum RecordType {
// Zero is reserved for preallocated files
kZeroType = 0,
kFullType = 1,
// For fragments
kFirstType = 2,
kMiddleType = 3,
kLastType = 4
};
static const int kMaxRecordType = kLastType;
static const int kBlockSize = 32768;
// Header is checksum (4 bytes), length (2 bytes), type (1 byte).
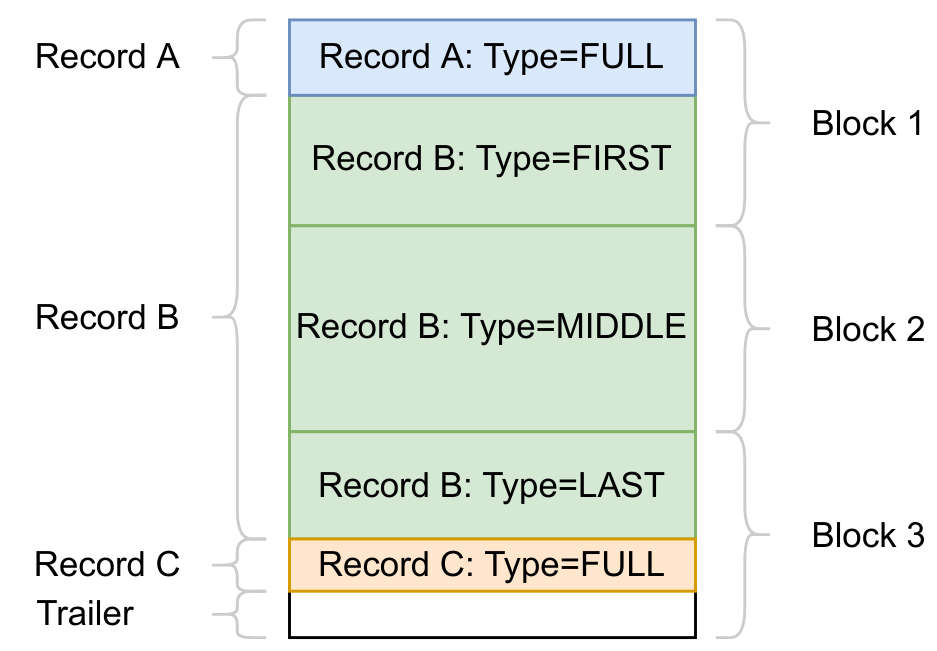
static const int kHeaderSize = 4 + 2 + 1;LogFile 由一系列的 32K 大小的 Block 构成,末尾的 Block 可以不足 32K ,一个 Block 由一组 record 加上末尾的 trailer 构成。
block := record* trailer?
record :=
checksum: uint32 // crc32c of type and data[] ; little-endian
length: uint16 // little-endian
type: uint8 // One of FULL, FIRST, MIDDLE, LAST
data: uint8[length]
types:
FULL == 1
FIRST == 2
MIDDLE == 3
LAST == 4- 当 Block 剩下的字节不足 7 个时(Record 长度至少 7 字节),会填充 0 字节,亦即 trailer。
- 当 Block 剩下的字节恰好为 7 个并且需要继续写数据时,会添加一个零长度的 FIRST 类型的 Record,需要写的数据会被写出到下一个 Block 。
对于 Record 的类型:
- FULL
- record 包含的用户数据是完整的。
- FIRST, MIDDLE, LAST
- 当 record 的用户数据被存放到连续的多个 record 时使用。
| uint32 | uint16 | uint8 | uint8[length] |
|---|---|---|---|
| checksum | length | type | data |
流程
创建与删除
在 DB::Open 和 MakeRoomForWrite 中会创建新 Log 文件,LogFile 和 Memtable 一一对应,LogFile 的创建时机就是创建新 Memtable 的时候:
s = env_->NewWritableFile(LogFileName(dbname_, new_log_number), &lfile);
Status NewWritableFile(const std::string& filename,
WritableFile** result) override {
int fd = ::open(filename.c_str(),
O_TRUNC | O_WRONLY | O_CREAT | kOpenBaseFlags, 0644);
if (fd < 0) {
*result = nullptr;
return PosixError(filename, errno);
}
*result = new PosixWritableFile(filename, fd);
return Status::OK();
}删除则是在 Immutable Memtable dump 成功(~DBImpl::CompactMemTable~)之后使用 DBImpl::RemoveObsoleteFiles 进行:
keep = ((number >= versions_->LogNumber()) ||
(number == versions_->PrevLogNumber()));写
- 组织
WriteBatch内的 KVs 为 Slice ,格式为:
// Value types encoded as the last component of internal keys.
// DO NOT CHANGE THESE ENUM VALUES: they are embedded in the on-disk
// data structures.
enum ValueType { kTypeDeletion = 0x0, kTypeValue = 0x1 };
void WriteBatch::Put(const Slice& key, const Slice& value) {
WriteBatchInternal::SetCount(this, WriteBatchInternal::Count(this) + 1);
rep_.push_back(static_cast<char>(kTypeValue));
PutLengthPrefixedSlice(&rep_, key);
PutLengthPrefixedSlice(&rep_, value);
}| Type | Key Lenght | Key Slice | Value Length | Value Slice |
|---|---|---|---|---|
| byte | varint32 | bytes | varint32 | bytes |
- 将
WriteBatch的存放多个 KVs 的 Slice 作为一个 Record 从上次 Block 写入的 Offset 继续写入,并按 Block 边界分段划分 Record 为子 Record。
Status Writer::AddRecord(const Slice& slice) {
const char* ptr = slice.data();
size_t left = slice.size();
// Fragment the record if necessary and emit it. Note that if slice
// is empty, we still want to iterate once to emit a single
// zero-length record
Status s;
bool begin = true;
do {
const int leftover = kBlockSize - block_offset_;
assert(leftover >= 0);
if (leftover < kHeaderSize) {
// Switch to a new block
if (leftover > 0) {
// Fill the trailer (literal below relies on kHeaderSize being 7)
static_assert(kHeaderSize == 7, "");
dest_->Append(Slice("\x00\x00\x00\x00\x00\x00", leftover));
}
block_offset_ = 0;
}
// Invariant: we never leave < kHeaderSize bytes in a block.
assert(kBlockSize - block_offset_ - kHeaderSize >= 0);
const size_t avail = kBlockSize - block_offset_ - kHeaderSize;
const size_t fragment_length = (left < avail) ? left : avail;
RecordType type;
const bool end = (left == fragment_length);
if (begin && end) {
type = kFullType;
} else if (begin) {
type = kFirstType;
} else if (end) {
type = kLastType;
} else {
type = kMiddleType;
}
s = EmitPhysicalRecord(type, ptr, fragment_length);
ptr += fragment_length;
left -= fragment_length;
begin = false;
} while (s.ok() && left > 0);
return s;
}- 子 Record 写入 LogFile 后进行 Sync 并计算偏移,成功后偏移才会移动。
Status Writer::EmitPhysicalRecord(RecordType t, const char* ptr,
size_t length) {
assert(length <= 0xffff); // Must fit in two bytes
assert(block_offset_ + kHeaderSize + length <= kBlockSize);
// Format the header
char buf[kHeaderSize];
buf[4] = static_cast<char>(length & 0xff);
buf[5] = static_cast<char>(length >> 8);
buf[6] = static_cast<char>(t);
// Compute the crc of the record type and the payload.
uint32_t crc = crc32c::Extend(type_crc_[t], ptr, length);
crc = crc32c::Mask(crc); // Adjust for storage
EncodeFixed32(buf, crc);
// Write the header and the payload
Status s = dest_->Append(Slice(buf, kHeaderSize));
if (s.ok()) {
s = dest_->Append(Slice(ptr, length));
if (s.ok()) {
s = dest_->Flush();
}
}
block_offset_ += kHeaderSize + length;
return s;
}读
。。。
Sync
Sync 即启用 WAL 的模式,此时在每次“写出” LogFile 后需要调用 Sync 方法:
- 按需更新 Manifest 文件
- 写出并移动 pos 指针
- 确保对应文件的内存中的页缓存写出到持久化设备中(Linux 同步写),
fcntl先按下不表,这里微妙的地方是使用fsync和fsyncdata的区别,前者会同时更新文件的元数据,而元数据和数据并不放在一起,这会导致磁盘至少多一次随机 I/O 时间,而假如文件大小不变且我们不更新文件的其他元数据(名称、更新时间等)fsyncdata是完全够用的,不过奇怪的地方是 leveldb 并没有预先创建好 log file 的 size ,所以实际上因为长度的改变还是会刷 metadata 的。
Status Sync() override {
// Ensure new files referred to by the manifest are in the filesystem.
//
// This needs to happen before the manifest file is flushed to disk, to
// avoid crashing in a state where the manifest refers to files that are not
// yet on disk.
Status status = SyncDirIfManifest();
if (!status.ok()) {
return status;
}
status = FlushBuffer(); // 写出并移动 pos_ 指针
if (!status.ok()) {
return status;
}
return SyncFd(fd_, filename_);
}
// Ensures that all the caches associated with the given file descriptor's
// data are flushed all the way to durable media, and can withstand power
// failures.
//
// The path argument is only used to populate the description string in the
// returned Status if an error occurs.
static Status SyncFd(int fd, const std::string& fd_path) {
#if HAVE_FULLFSYNC
// On macOS and iOS, fsync() doesn't guarantee durability past power
// failures. fcntl(F_FULLFSYNC) is required for that purpose. Some
// filesystems don't support fcntl(F_FULLFSYNC), and require a fallback to
// fsync().
if (::fcntl(fd, F_FULLFSYNC) == 0) {
return Status::OK();
}
#endif // HAVE_FULLFSYNC
#if HAVE_FDATASYNC
bool sync_success = ::fdatasync(fd) == 0;
#else
bool sync_success = ::fsync(fd) == 0;
#endif // HAVE_FDATASYNC
if (sync_success) {
return Status::OK();
}
return PosixError(fd_path, errno);
}评价
Pros:
- 简单易读
- 容易对 Record 做拆分
- 对于大 Record 不需要额外的缓冲
Cons:
- 没有很好地利用
fdatasync - 没有做压缩